概览
rocketmq 默认存储根目录是 $HOME/store,可以在修改配置文件中进行更改1
storePathRootDir=$HOME/store
rocketmq 默认存储根目录结构,如下
1 | # tree store |
rocketmq 存盘的数据有 6 类,其中有 3 类小文件:
- abort
- checkpoint
config
topics.json 存储每个 topic 的读写队列数、权限、是否顺序等信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18{
"dataVersion":{
"counter":285,
"timestatmp":1557378378161
},
"topicConfigTable":{
"updateReserveMQTopic":{
"order":false,
"perm":6,
"readQueueNums":4,
"topicFilterType":"SINGLE_TAG",
"topicName":"updateReserveMQTopic",
"topicSysFlag":0,
"writeQueueNums":4
},
...
}
}consumerOffset.json 存储每个 consumer 在每个 topic consumequeue 队列的消费进度
1
2
3
4
5
6
7{
"offsetTable":{
"artisanDetailBrowseMqTopic@artisanUserRelationMqConsumerGroup":{0:150,2:104,1:120,3:89
},
...
}
}delayOffset.json文 存储对于延迟 topic 每个consumequeue 队列的消费进度
subscriptionGroup.json 存储每个 consumer 的订阅信息
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19{
"dataVersion":{
"counter":36,
"timestatmp":1557368823539
},
"subscriptionGroupTable":{
"orderCenter":{
"brokerId":0,
"consumeBroadcastEnable":true,
"consumeEnable":true,
"consumeFromMinEnable":true,
"groupName":"orderCenter",
"retryMaxTimes":16,
"retryQueueNums":1,
"whichBrokerWhenConsumeSlowly":1
},
...
}
}
还有 3 类大文件:
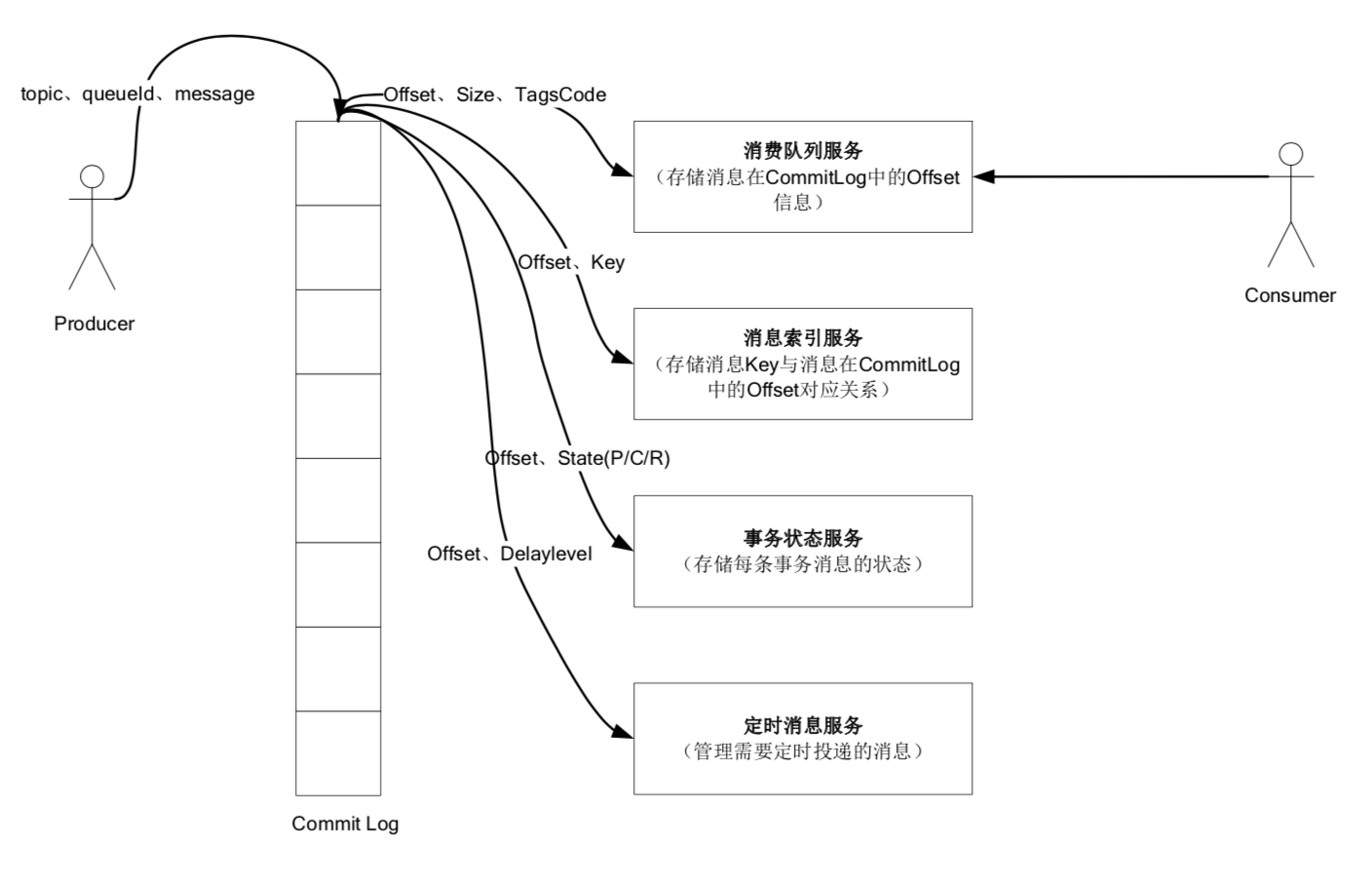
- commitlog: 存储 rocketmq 所有消息的元数据信息
- consumequeue: 消息队列,存储消息在 commitlog 的位置信息
- index: 索引,可根据 key 查询到对应的消息
commitlog
commitlog + consumequeue

rocketmq 数据存储的特点:
- 所有消息的元数据都单独存储到 commitlog 里,完全顺序写,随机读
- 对最终用户展现的消息队列 consumequeue,实际只存储消息在 commitlog 的位置信息,串行方式刷盘
这样做的好处:
- 消息队列轻量化,单个队列数据量非常少
- 对磁盘的访问串行化,避免磁盘竟争,不会因为队列增加导致IOWAIT增高
缺点是:
- 写虽然完全是顺序写,但是读却变成了完全的随机读
- 读一条消息,要先读 consumequeue,再读 commitlog,增加了开销
- 要保证 commitlog 与 consumequeue 完全的一致,增加了编程的复杂度
如何克服以上缺点呢?
- 随机读,尽可能让读命中 PAGECACHE,减少 IO 读操作,所以内存越大越好
- 由于 consumequeue 存储数据量极少,而且是顺序读,在PAGECACHE预读作用下,consumequeue的读
性能几乎与内存一致,可认为 consumequeue 完全不会阻碍读性能 - commitlog 中存储了所有的元信息,包含消息体,只要有 commitlog 在,consumequeue 即使数据丢失,仍然可以恢复出来
commitlog 文件特点
- commitlog 每个文件的大小固定不变,默认是 1GB = 102410241024B = 1073741824 Bytes
- commitlog 文件的文件名,长度为20位,为起始偏移量,左边补零
- 00000000000000000000 代表了第一个文件,起始偏移量为0,文件大小为1G=1073741824;当这个文件满了,第二个文件名为00000000001073741824,起始偏移量为1073741824,以此类推,第三个文件名字为00000000002147483648,起始偏移量为2147483648
- 消息存储时,顺序写入文件,当文件满了,写入下一个文件
存储结构
commitlog 文件中,有两种单元类型:
- MESSAGE: 消息单元
- BLANK: 空白占位单元,文件不足以存储消息时, 填充空白占位
| MESSAGE[1] | MESSAGE[2] | … | MESSAGE[n - 1] | MESSAGE[n] | BLANK |
|---|---|---|---|---|---|
MESSAGE 消息单元存储结构
| 第几位 | 字段 | 说明 | 数据类型 | 字节数 |
|---|---|---|---|---|
| 1 | MsgLen | 消息总长度 | Int | 4 |
| 2 | MagicCode | MESSAGE_MAGIC_CODE | Int | 4 |
| 3 | BodyCRC | 消息内容CRC | Int | 4 |
| 4 | QueueId | 消息队列编号 | Int | 4 |
| 5 | Flag | flag | Int | 4 |
| 6 | QueueOffset | 消息队列位置 | Long | 8 |
| 7 | PhysicalOffset | 物理位置: commitlog 文件中的顺序存储位置 | Long | 8 |
| 8 | SysFlag | MessageSysFlag | Int | 4 |
| 9 | BornTimestamp | 生成消息时间戳 | Long | 8 |
| 10 | BornHost | 生成消息的 ip + 端口 | Long | 8 |
| 11 | StoreTimestamp | 存储消息时间戳 | Long | 8 |
| 12 | StoreHost | 存储消息的 ip + 端口 | Long | 8 |
| 13 | ReconsumeTimes | 重新消费消息次数 | Int | 4 |
| 14 | PreparedTransationOffset | Long | 8 | |
| 15 | BodyLength + Body | 内容长度 + 内容 | Int + Bytes | 4 + bodyLength |
| 16 | TopicLength + Topic | Topic长度 + Topic | Byte + Bytes | 1 + topicLength |
| 17 | PropertiesLength + Properties | 拓展字段长度 + 拓展字段 | Short + Bytes | 2 + PropertiesLength |
BLANK 空白占位单元存储结构
| 第几位 | 字段 | 说明 | 数据类型 | 字节数 |
|---|---|---|---|---|
| 1 | maxBlank | 空白长度 | Int | 4 |
| 2 | MagicCode | BLANK_MAGIC_CODE | Int | 4 |
其中,MESSAGE_MAGIC_CODE、BLANK_MAGIC_CODE 是在 org.apache.rocketmq.store.CommitLog 中定义的
1 | // Message's MAGIC CODE daa320a7 |
MessageSysFlag 是在 org.apache.rocketmq.common.sysflag.MessageSysFlag 中定义的,值为 1 表示 commitlog 实际存储的该条消息 body 是 zip 压缩过,需要 unzip 解压才能得到原始的消息 (默认 body >= 4KB 就会进行 zip 压缩)1
2
3
4
5
6public final static int COMPRESSED_FLAG = 0x1;
public final static int MULTI_TAGS_FLAG = 0x1 << 1;
public final static int TRANSACTION_NOT_TYPE = 0;
public final static int TRANSACTION_PREPARED_TYPE = 0x1 << 2;
public final static int TRANSACTION_COMMIT_TYPE = 0x2 << 2;
public final static int TRANSACTION_ROLLBACK_TYPE = 0x3 << 2;
consumequeue
consumequeue 文件特点
1 | store |
- consumequeue 文件,按照 topic、queue_id 分目录存储
- consumequeue 每个文件的大小固定不变,大小为 600W Bytes
- 每个文件由 30W 个数据单元组成,每个数据单元 20 Bytes
- cosumequeue 文件名,名字长度为20位,为起始偏移量,左边补零
- 00000000000000000000 代表了第一个文件,起始偏移量为0,文件大小为600W,当第一个文件满之后创建的第二个文件的名字为00000000000006000000,起始偏移量为6000000,以此类推,第三个文件名字为00000000000012000000,起始偏移量为12000000
- 消息存储时,顺序写入文件,当文件满了,写入下一个文件
存储结构
consumequeue 文件中,有两种单元类型:
MESSAGE_POSITION_INFO:消息位置信息BLANK: 空白占位 (当历史Message被删除时,需要用BLANK占位被删除的消息)

MESSAGE_POSITION_INFO 存储结构
| 第几位 | 字段 | 说明 | 数据类型 | 字节数 |
|---|---|---|---|---|
| 1 | offset | 消息在 commitlog 中的存储位置 | Long | 8 |
| 2 | size | 消息长度 | Int | 4 |
| 3 | tagsCode | 消息tagsCode | Long | 8 |
注: tagsCode 字段是 tags 的 hashCode,采用 java.lang.String#hashCode,也即 s[0]31^(n-1) + s[1]31^(n-2) + … + s[n-1]
BLANK 存储结构
| 第几位 | 字段 | 说明 | 数据类型 | 字节数 |
|---|---|---|---|---|
| 1 | 0 | Long | 8 | |
| 2 | Integer.MAX_VALUE | Int | 4 | |
| 3 | 0 | Long | 8 |
index
index 文件特点


- index 每个文件的大小固定不变,大小为 40 + 500W4 + 2000W20 = 420000040 Bytes
- index 文件名,是创建时的时间戳,如 20190425105434433
- index 的逻辑结构,与 HashMap 实现类似
Header
| beginTimestamp | endTimestamp | beginPhyOffset | endPhyOffset | hashSlotCount | indexCount |
|---|---|---|---|---|---|
| 8 Bytes | 8 Bytes | 8 Bytes | 8 Bytes | 4 Bytes | 4 Bytes |
Index Header 各字段含义:
beginTimestamp:第一个索引消息存储时间戳;
endTimestamp:最后一个索引消息存储时间戳;
beginPhyOffset:第一个索引消息在 commitlog 的偏移量;
endPhyOffset:最后一个索引消息在 commitlog 的偏移量;
hashSlotCount:该索引文件目前的hash slot的个数;
indexCount:该索引文件目前的消息索引个数;
Slot Table
- 根据 key 定位 Slot Table 的位置及在 index 文件中的偏移量 absSlotPos
1 | // hashSlotNum = 500W, INDEX_HEADER_SIZE = 40, hashSlotSize = 4 |
- slot 位置存储的值 (slotValue) 是该槽位索引链表的最新索引当时的 index count 值
- 索引当时的 index count 值,相当于序号,因为索引是固定长度的,有了这个序号,就可以计算得到该索引的 absIndexPos
- 链表倒序排列,slotValue 总是指向最新的一个索引项,每次该槽位新增索引项时,slotValue 更新为这个新增的索引项
Index Linked List
| keyHash | phyOffset | timeDiff | slotValue |
|---|---|---|---|
| 4 Bytes | 8 Bytes | 4 Bytes | 4 Bytes |
Index Linked List 各字段含义:
keyHash: key 的 hash 值;
phyOffset: commitLog 真实的物理偏移值;
timeDiff:时间偏移值,消息的存储时间与 Index Header 中 beginTimestamp 的时间差 (目的是为了节省空间);
slotValue:指向上一个索引项,从而形成一个链表结构;
Index Linked List的位置(absIndexPos)的计算1
2// hashSlotNum = 500W, INDEX_HEADER_SIZE = 40, hashSlotSize = 4, indexSize = 20
int absIndexPos = IndexHeader.INDEX_HEADER_SIZE + hashSlotNum * hashSlotSize + indexCount * indexSize;
添加索引 putKey
org.apache.rocketmq.store.index.IndexFile#putKey
1 | public boolean putKey(final String key, final long phyOffset, final long storeTimestamp) { |
索引查询 selectPhyOffset
org.apache.rocketmq.store.index.IndexFile#selectPhyOffset
1 | public void selectPhyOffset(final List<Long> phyOffsets, final String key, final int maxNum, |
Hash 冲突
寻找 key 的 slot 位置时,相当于执行了两次散列函数,一次是计算 key 的 hash,一次 key 的 hash 值取模,
因此这里存在两次冲突的情况:
- 第一种,key 的 hash 值不同但模数相同,此时查询的时候会在比较一次 key 的 hash 值(每个索引项保存了 key 的 hash 值),过滤掉 hash 值不相等的项
- 第二种,hash 值相等但 key 不等, 出于性能的考虑,冲突的检测放到客户端处理(key 的原始值是存储在消息文件中的,避免对数据文件的解析), 客户端比较一次消息体的 key 是否相同
附 rocketmq_parser.py
1 | #!/usr/bin/python |
参考
本文参考了互联网上大家的分享,就不一一列举,在此一并谢过。
也希望本文,能对大家有所帮助,若有错误,还请谅解、指正。