Unix/Linux IO
服务端处理网络请求
服务端处理网络请求的典型过程: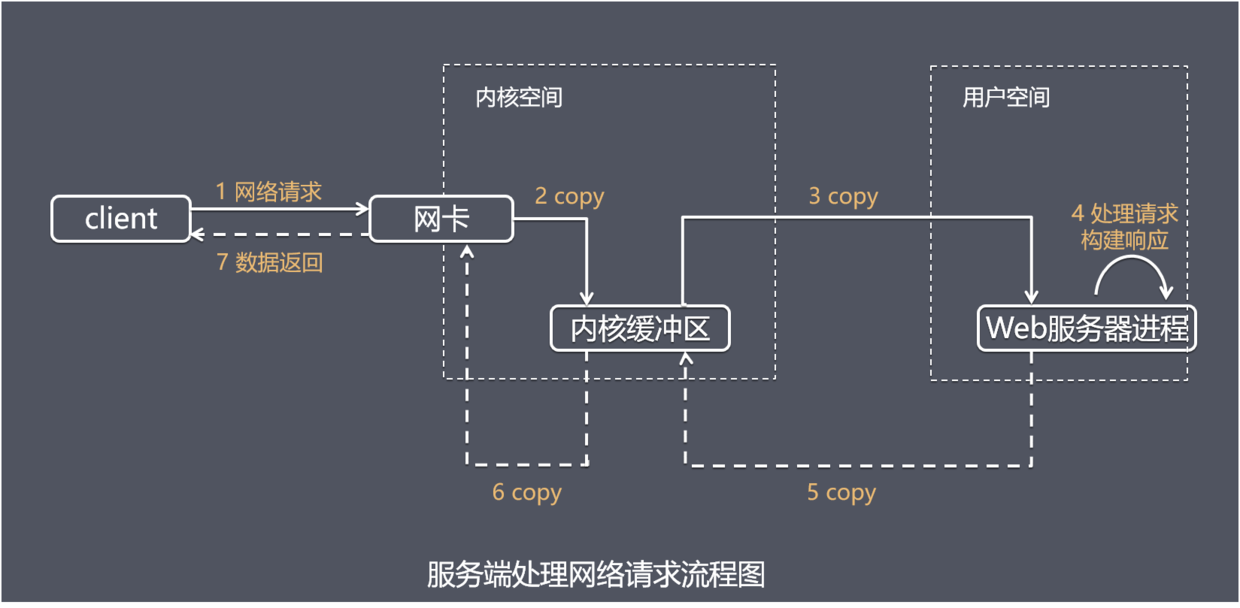
一个输入操作通常包括两个不同的阶段:
- 等待数据准备好
- 从内核向用户进程复制数据
第一步通常涉及等待数据从网络中到达。当所等待分组到达时,它被复制到内核中的某个缓冲区。
第二步就是把数据从内核缓冲区复制到应用进程缓冲区
Intel CPU 提供Ring0-Ring3四种级别的运行模式,Ring0级别最高,Ring3最低。Linux使用了Ring3级别运行用户态,Ring0作为内核态。Ring3状态不能访问Ring0的地址空间,包括代码和数据。因此用户态是没有权限去操作内核态的资源的,它只能通过系统调用外完成用户态到内核态的切换,然后在完成相关操作后再有内核态切换回用户态。
应用程序在系统调用完成上面2步操作时,调用方式的阻塞、非阻塞,操作系统在处理应用程序请求时处理方式的同步、异步处理的不同,参考 《UNIX网络编程.卷1》,可以分为5种I/O模型
IO模型
1. 阻塞式I/O模型(blocking I/O)
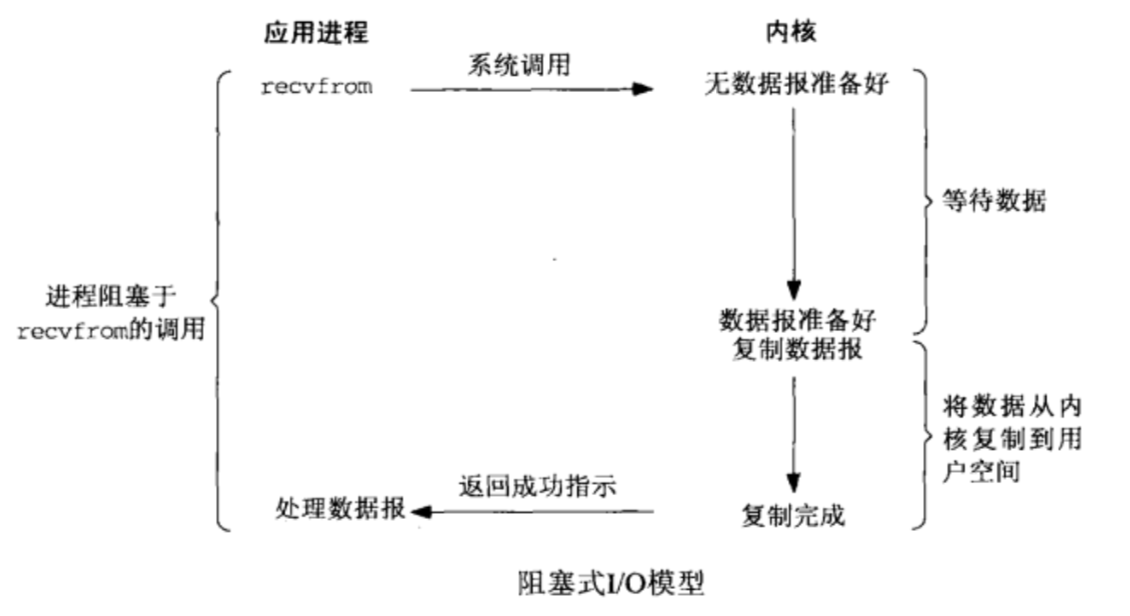
在阻塞式I/O模型中,应用程序在从调用recvfrom开始到它返回有数据报准备好这段时间是阻塞的,recvfrom返回成功后,应用进程开始处理数据报。
比喻 一个人在钓鱼,当没鱼上钩时,就坐在岸边一直等
优点 线程模型简单,方便开发
缺点 每个连接需要独立的进程/线程单独处理,当并发请求量大时为了维护程序,内存、线程频繁切换开销较大
2. 非阻塞式I/O模型(non-blocking I/O)
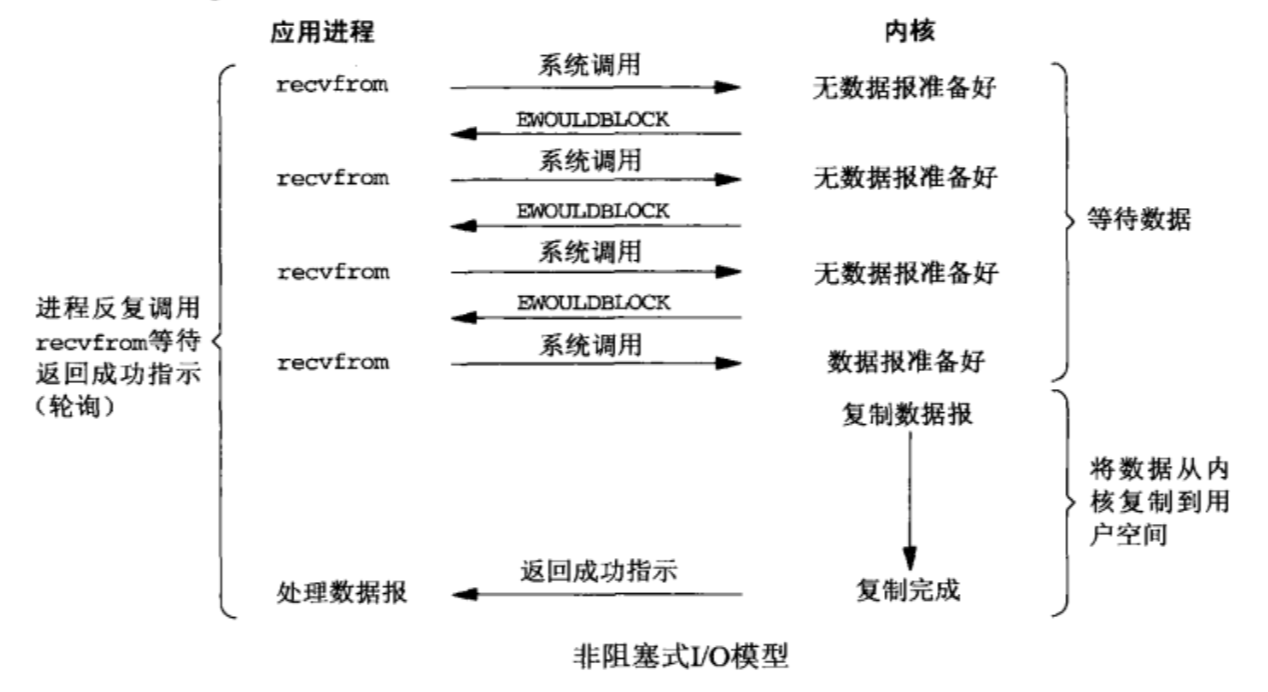
在非阻塞式I/O模型中,应用程序把一个套接字设置为非阻塞就是告诉内核,当所请求的I/O操作无法完成时,不要将进程睡眠,而是返回一个错误,应用程序基于I/O操作函数将不断的轮询数据是否已经准备好,如果没有准备好,继续轮询,直到数据准备好为止。
比喻 边钓鱼边玩手机,隔会再看看有没有鱼上钩,有的话就迅速拉杆
优点 不会阻塞在内核的等待数据过程,每次发起的I/O请求可以立即返回,不用阻塞等待,实时性较好
缺点 轮询将会不断地询问内核,这将占用大量的CPU时间,系统资源利用率较低,所以一般情况不会使用这种I/O模型
3. I/O复用模型(I/O multiplexing)
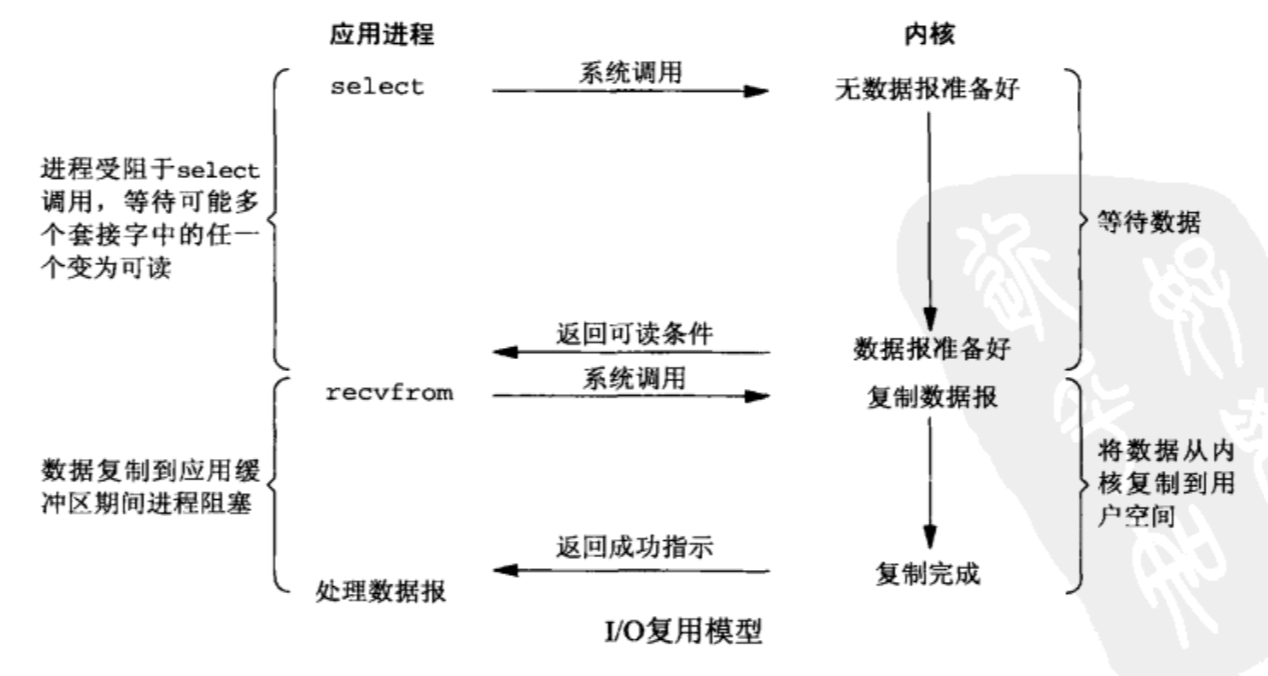
在I/O复用模型中,select 系统调用也会使进程阻塞,但是和阻塞I/O所不同的的,阻塞在 select 系统调用上,等待多个套接字中的任一个变为可读,而不是阻塞在真正的 I/O 系统调用 recvfrom 上。
比喻 放了一堆鱼竿,在岸边一直守着这堆鱼竿,直到有鱼上钩
优点 可以基于一个阻塞对象,同时在多个描述符上等待就绪,而不是使用多个线程(每个文件描述符一个线程),这样可以大大节省系统资源
缺点 当连接数较少时效率相比多线程+阻塞I/O模型效率较低,可能延迟更大,因为单个连接处理需要2次系统调用 (select + recvfrom),占用时间会有增加
疑问 ?
I/O 复用模型,I/O 本身的调用是非阻塞的吧!
scalable I/O event notification mechanism:
- POSIX: select, poll
- Linux: epoll
- FreeBSD: kqueue (macOS)
select:上世纪 80 年代就实现了,它支持注册 FD_SETSIZE(1024) 个 socket,在那个年代肯定是够用的,现在肯定是不行的。
poll:1997 年,出现了 poll 作为 select 的替代者,最大的区别就是,poll 不再限制 socket 数量。
select 和 poll 都有一个共同的问题,那就是它们都只会告诉你有几个通道准备好了,但是不会告诉你具体是哪几个通道。所以,一旦知道有通道准备好以后,自己还是需要进行一次扫描,显然这个不太好,通道少的时候还行,一旦通道的数量是几十万个以上的时候,扫描一次的时间都很可观了,时间复杂度 O(n)。所以,后来才催生了以下实现。
epoll:2002 年随 Linux 内核 2.5.44 发布,epoll 能直接返回具体的准备好的通道,时间复杂度 O(1)。
除了 Linux 中的 epoll,2000 年 FreeBSD 出现了 Kqueue,还有就是,Solaris 中有 /dev/poll。
Windows 平台的非阻塞 IO 使用的是 select,但是 Windows 中 IOCP 提供的异步 IO 非常强大。
4. 信号驱动式I/O模型(signal-driven I/O) [ˈdrɪvn]
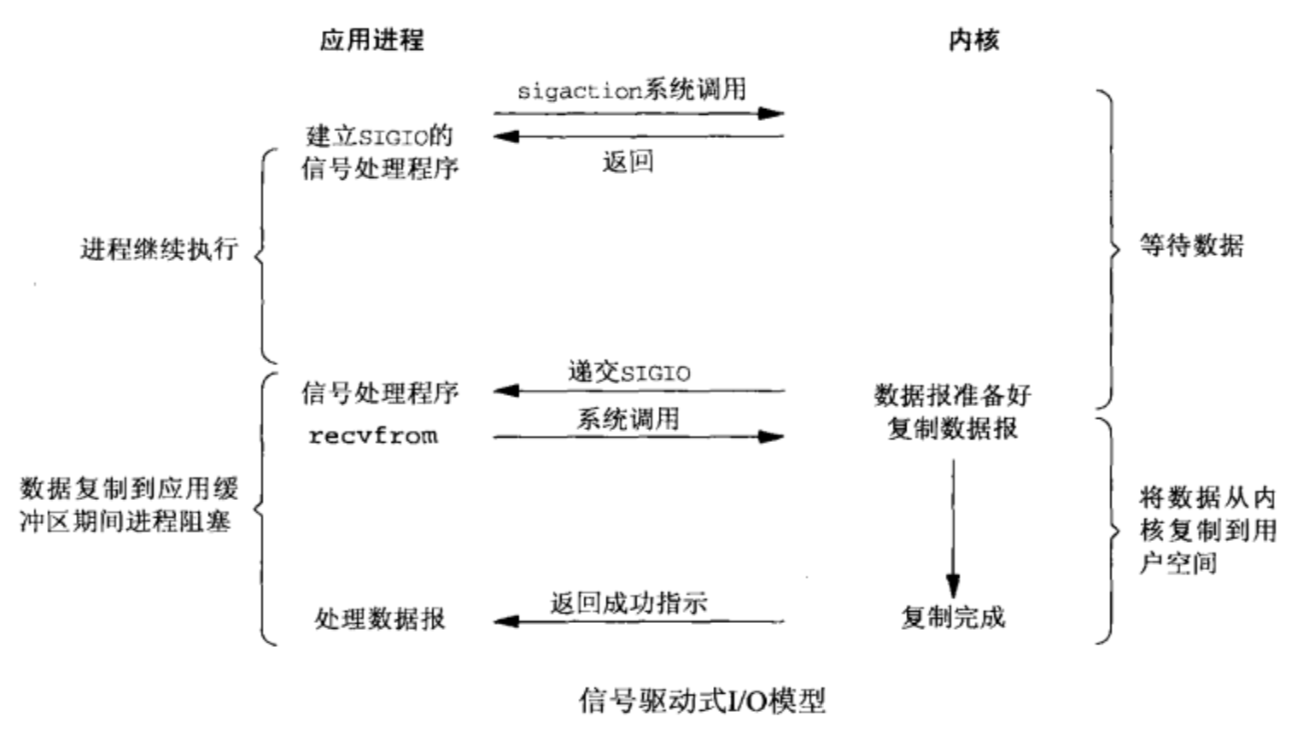
应用程序首先开启套接字的信号驱动式I/O功能,并通过sigaction系统调用安装一个信号处理函数,该系统调用将立即返回,进程继续运行并不阻塞。当数据准备好时,进程会收到内核产生的一个SIGIO信号,随后可以在信号处理函数中调用I/O操作函数 recvfrom 读取数据。
比喻 鱼竿上系了个铃铛,当铃铛响,就知道鱼上钩,然后可以专心玩手机
5. 异步I/O模型(asynchronous I/O)

由POSIX规范定义,应用程序告知内核启动某个操作,并让内核在整个操作(包括将数据从内核复制到应用程序自己的缓冲区)完成后通知应用程序。这种模型与信号驱动模型的主要区别在于:信号驱动I/O是由内核通知应用程序何时启动一个I/O操作,而异步I/O模型是由内核通知应用程序I/O操作何时完成。
优点 系统资源利用率高
缺点 要实现真正的异步 I/O,操作系统需要做大量的工作。目前 Windows 下通过 IOCP 实现了真正的异步 I/O,而在 Linux 系统下,Linux2.6才引入,目前 AIO 并不完善,因此在 Linux 下实现高并发网络编程时都是以 IO复用模型模式为主。
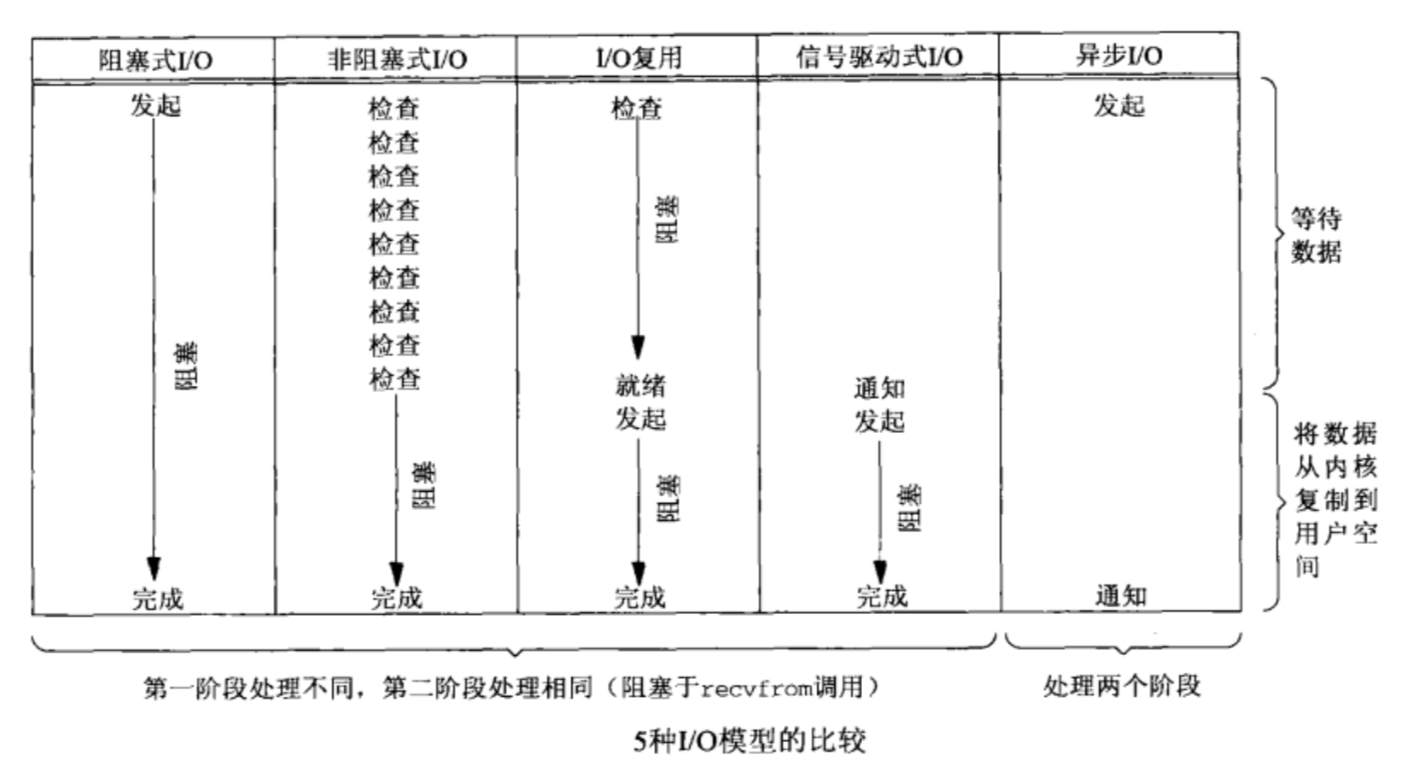
5种I/O模型总结
POSIX 对同步I/O、异步I/O 这两个术语的定义如下:
- A synchronous I/O operation causes the requesting process to be blocked until that I/O operation completes. 同步I/O在直到 I/O 操作完成期间,会导致请求进程阻塞
- An asynchronous I/O operation does not cause the requesting process to be blocked. 异步I/O在直到 I/O 操作完成期间,都不会导致请求进程阻塞
从上图中我们可以看出,可以看出,越往后,阻塞越少,理论上效率也是最优。其五种I/O模型中,前四种属于同步I/O,因为其中真正的I/O操作(recvfrom)将阻塞进程/线程,只有异步I/O模型才于POSIX定义的异步I/O相匹配。
I/O 复用模型 与 AIO 相比,就是多了一层从内核copy数据到应用空间的阻塞,从而不能算作asynchronous I/O类。但是,这层小小的阻塞无足轻重。
NIO
官方称之为 New IO,也有人称之为 Non-Blocking IO。
NIO 对应的是上面 I/O复用模型(I/O multiplexing)。
有些人喜欢将 NIO 称为 异步非阻塞 IO,但是如果严格按照 POSIX 定义,它并不是异步 IO。
不过也不必纠结于术语,知道其中的道理就好。
NIO vs IO
- 标准 IO 基于 流 (Stream) 进行操作;NIO 是基于 通道 (Channel) 进行操作的。
- Channel 是双向的,既可以写数据到通道,又可以从通道中读取数据,它能更好地反映出底层操作系统的真实情况(Linux 底层网络 IO 就是双向的);而流的读写只能是单向的,要么是输入流,要么是输出流,不能既是输入流又是输出流。
- NIO能够实现阻塞/非阻塞的网络通信,而IO只能实现阻塞式的网络通信。
示例
NioServer
1 | public class NioServer { |
client1
$ nc 127.0.0.1 7788
NioClient
1 | public class NioClient { |
NIO API
Buffer
一个 Buffer 本质上是内存中的一块,我们可以将数据写入这块内存,之后从这块内存获取数据。
NIO 通道 只能与 Buffer 进行交互。数据总是从通道读取到缓冲区,或者从缓冲区写入到通道中。
属性:
capacity:容量,永远不会变化
limit:不应该被读或写的第一个元素的索引
position:下一个将要被读或写的元素的索引
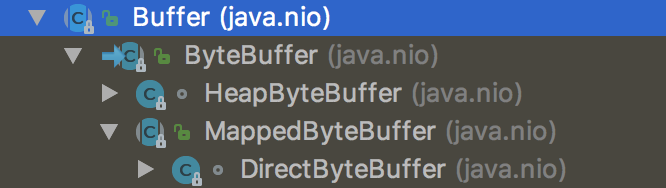
java.nio.Buffer
1 | public abstract class Buffer { |
java.nio.ByteBuffer
1 | public abstract class ByteBuffer extends Buffer |
Selector
SelectionKey
SocketChannel
ServerSocketChannel
Reactor
Event-driven processing pattern: Reactor, Proactor
Scalable IO in Java
Reactor
- Reactor responds to IO events by dispatching the appropriate handler
- Handlers perform non-blocking actions
- Manage by binding handlers to events
在中,Reactor等待某个事件或者可应用或个操作的状态发生(比如文件描述符可读写,或者是socket可读写),然后把这个事件传给事先注册的Handler(事件处理函数或者回调函数),由后者来做实际的读写操作,其中的读写操作都需要应用程序同步操作,所以Reactor是非阻塞同步网络模型。
如果把I/O操作改为异步,即交给操作系统来完成能进一步提升性能,这就是异步网络模型Proactor。
single threaded version
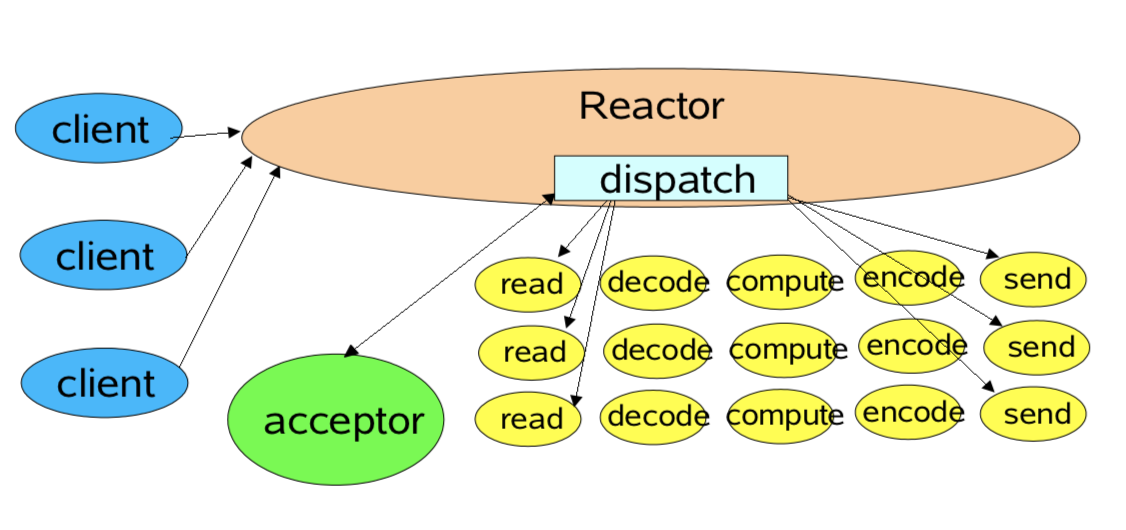
- Basic Reactor Design
- single threaded version
示例即是这一种,单线程管天下
后面两种 Multithreaded Designs
Strategically add threads for scalability
Mainly applicable to multiprocessors
worker thread pools
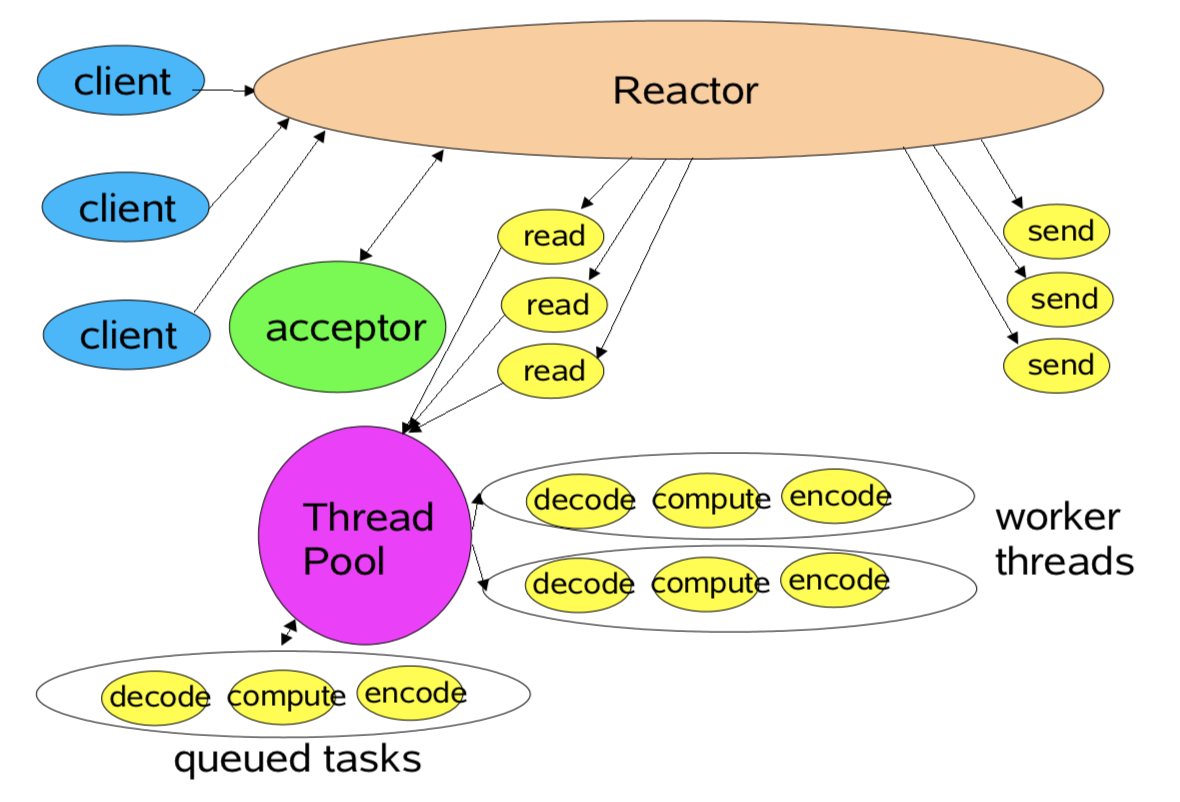
- Worker Threads
- Offload non-IO processing to speed up Reactor thread
- Similar to POSA2 Proactor designs
- Offload non-IO processing to speed up Reactor thread
multiple reactor threads
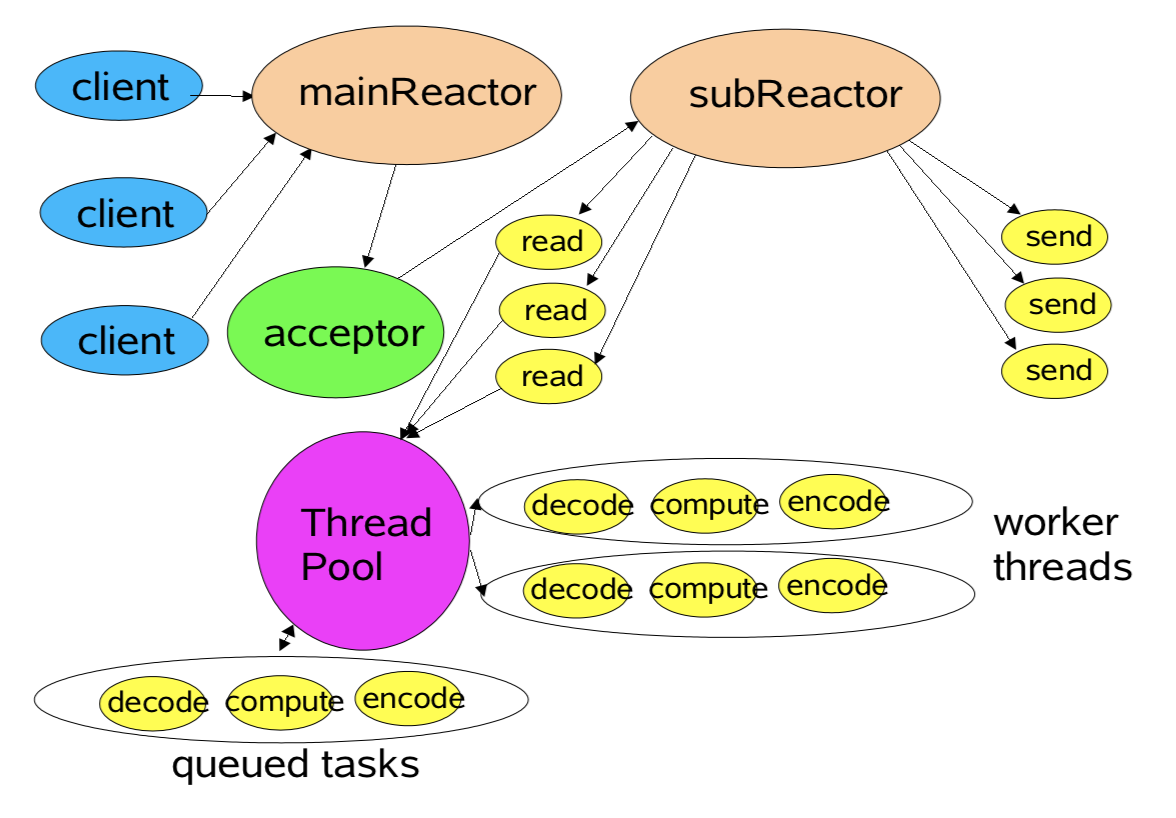
- Using Reactor Pools
- Load-balance to match CPU and IO rates
- Static or dynamic construction
- Each with own Selector, Thread, dispatch loop
- Main acceptor distributes load to other reactors
Java 原生 NIO 编程的缺点
- NIO的类库和API繁杂,使用麻烦,你需要熟练掌握Selector、ServerSocketChannel、SocketChannel、ByteBuffer等。
- 需要具备其他的额外技能做铺垫,例如熟悉Java多线程编程。这是因为NIO编程涉及到Reactor模式,你必须对多线程和网路编程非常熟悉,才能编写出高质量的NIO程序。
- 可靠性能力补齐,工作量和难度都非常大。例如客户端面临断连重连、网络闪断、粘包拆包、失败缓存、网络拥塞和异常码流的处理等问题,NIO编程的特点是功能开发相对容易,但是可靠性能力补齐的工作量和难度都非常大。
- JDK NIO的BUG,例如臭名昭著的epoll bug,它会导致Selector空轮询,最终导致CPU 100%。官方声称在JDK1.6版本的update18修复了该问题,但是直到JDK1.7版本该问题仍旧存在,只不过该BUG发生概率降低了一些而已,它并没有被根本解决。该BUG以及与该BUG相关的问题单可以参见以下链接内容。
http://bugs.java.com/bugdatabase/view_bug.do?bug_id=6403933
http://bugs.java.com/bugdatabase/view_bug.do?bug_id=2147719
示例中,只是 NIO 编程的演示代码,缺少太多功能:
- 没有实现 multiple reactor pattern
- 无论是 client 还是 server 都不能主动发送消息
- 没有编码、解码
- 没有考虑粘包、拆包
- 没有长连接心跳机制
大家可以试着完成这些功能,将有助于理解 netty 原理,因为有名的 netty 实际是基于 Java 原生 NIO 做了良好的封装,让 NIO 使用更方便、更省心、更健壮、功能更丰富、性能更好。
参考
本文参考了互联网上大家的分享,就不一一列举,在此一并谢过。
也希望本文,能对大家有所帮助,若有错误,还请谅解、指正。